医保数据库样本量大、随访长——这也意味着方法学缺陷会在规模上被放大。时变协变量处理不当、ICD 编码映射错误、队列入组标准不一致,每一项都可能导致系统性偏倚。
所有图表均为 synthetic illustrative data,由言拓致优内部生成,仅用于方法学路径展示,不指向任何真实患者或客户项目。
医保数据库、电子病历(EMR)等真实世界数据(RWD)的方法学挑战与 RCT 截然不同:数据量大但质量参差、ICD 编码存在版本差异和临床使用习惯偏差、合并症记录不完整、以及大量涉及"时间"的偏倚陷阱——Immortal Time Bias、时变混杂、竞争风险。
最容易被 reviewer 抓到的问题有两类:第一,暴露起点(index date)定义不清晰导致 immortal time 进入分析——这会系统性地让暴露组看起来有"保护效应";第二,长期慢性病研究忽视时变协变量——患者在随访期间的合并症、用药、血压等状态会动态变化,如果只取基线值建模,模型的效应估计是有偏的。
本类研究的方法学重点:严格的 ICD 编码映射 + 暴露-随访时间轴对齐 + 多重插补处理大规模缺失 + 时变协变量 Cox 模型 + 4 类敏感性分析(限制暴露时间/亚组/E-value/负对照)。
构建 ICD-9 → ICD-10 双向映射表(含临床常用同义码),逐库核查主诊断、次诊断、手术操作码的编码一致性。输出标准化变量字典 + 每个关键变量在各库中的频率分布对比——频率分布异常往往暗示编码习惯差异,需在方法节说明处理策略。
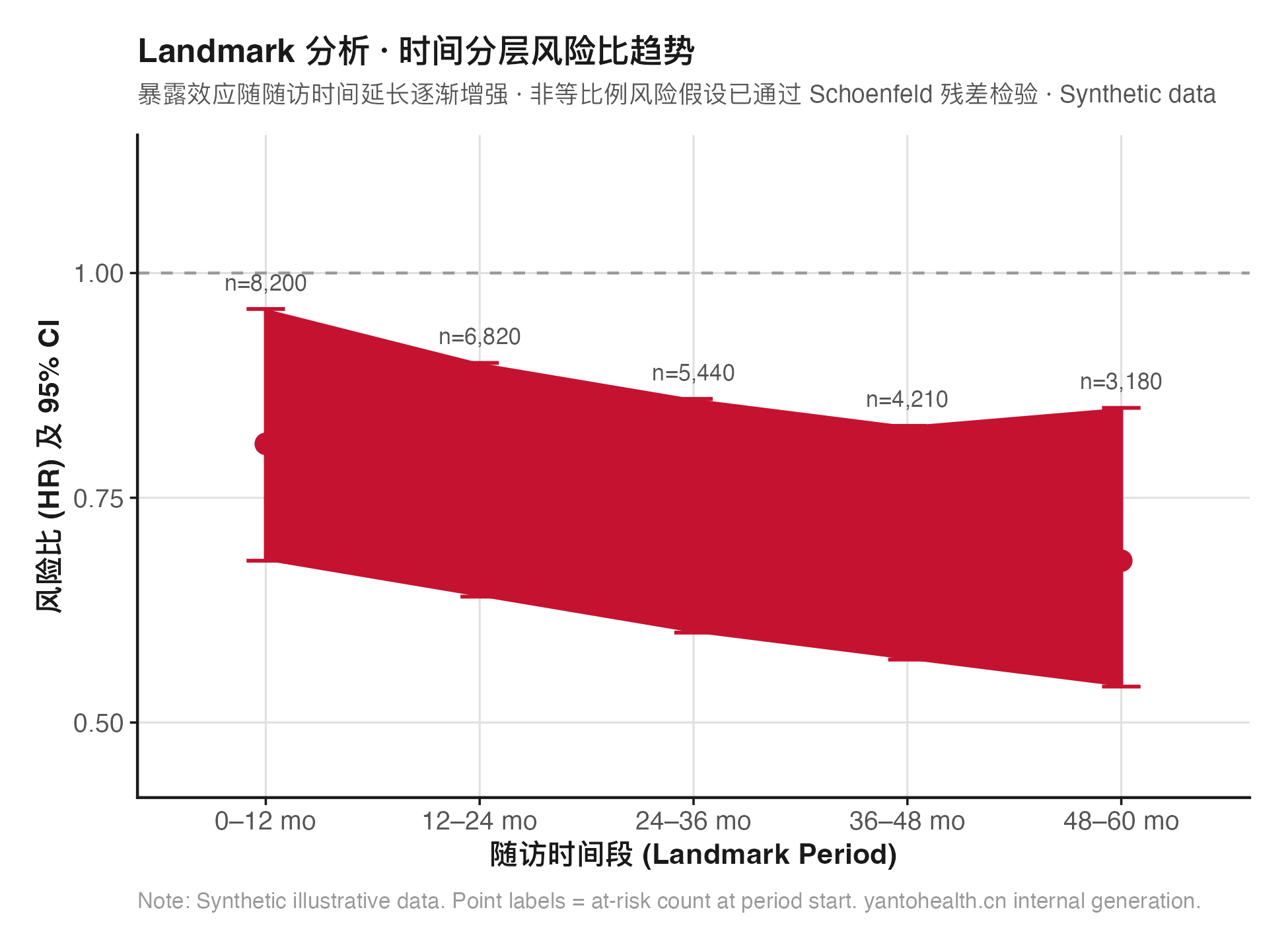
明确三个时间点:①队列入组日期(cohort entry date)②暴露起点(index date,必须 ≥ entry date)③事件发生或删失时间(event/censor date)。entry → index 之间的"等待期"若计入暴露组随访时间,将产生 immortal time bias。使用 landmark analysis 或 time-conditional exposure 定义规避。
真实世界数据缺失率通常较高(如实验室指标缺失 15–40%)。MICE(多重链式方程插补)生成 10–20 个插补数据集,逐数据集建模后用 Rubin's rules 合并效应量。插补模型中纳入结局变量(避免单调缺失 MAR 假设违反),报告各关键变量缺失率矩阵。
将随访期内动态变化的协变量(血压、用药状态、合并症)处理为时变格式(counting process format:start-stop 数据结构)。时变 Cox 模型使用 R 的 survival 包,tmerge() 函数构建时变数据框。比例风险假定检验仍适用(Schoenfeld 残差),违反则引入时间分层。
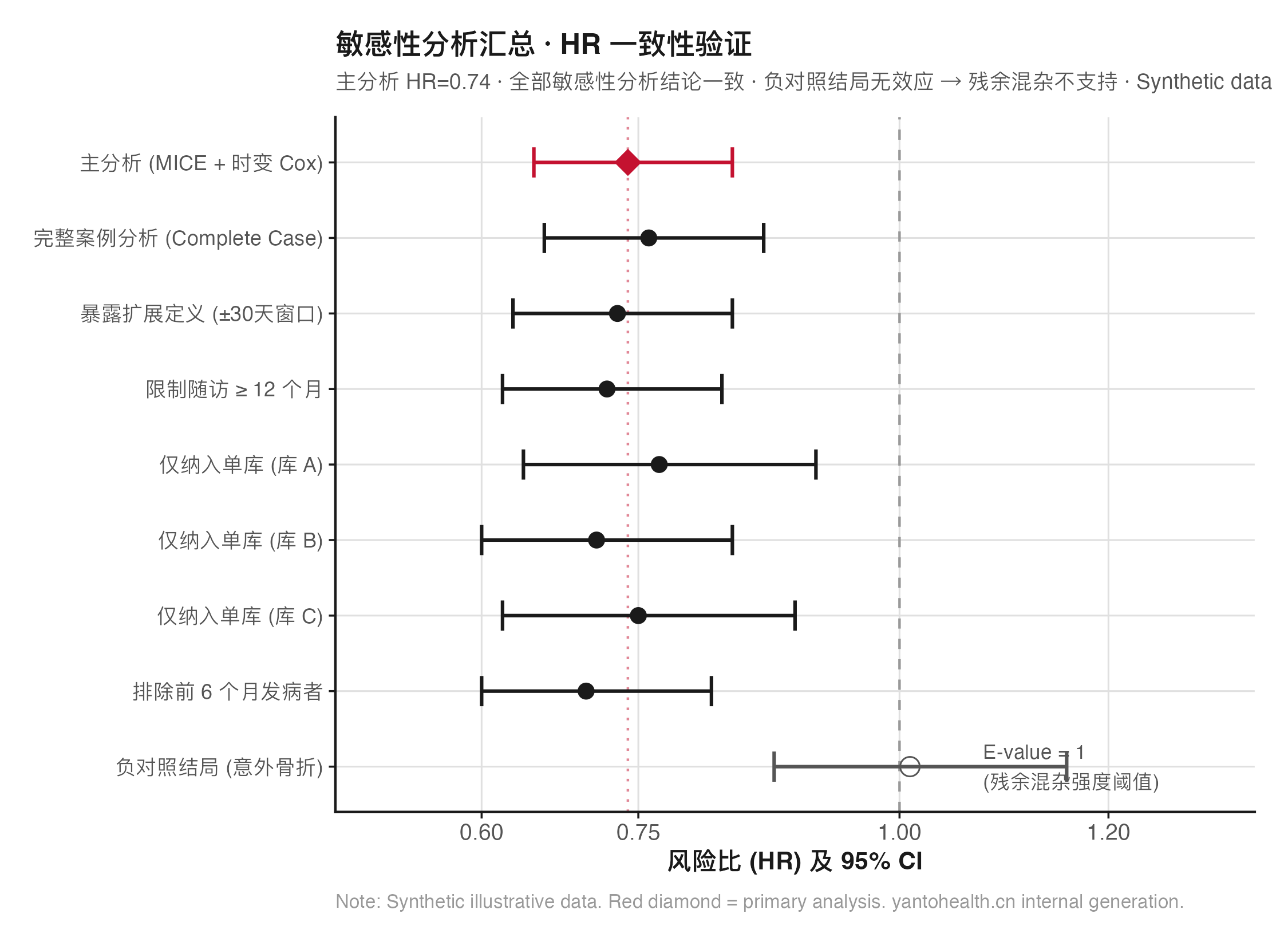
①限制暴露时间窗(仅纳入随访>12个月者消除短期存活偏倚)②不同随访截止时间敏感性②完整案例分析 vs MICE 对比③负对照结局分析(理论上暴露不影响该结局,验证有无残余混杂信号)。E-value 计算并报告,量化残余混杂阈值。
基于内部 600+ 项目质疑记录整理,不代表特定期刊或审稿人。
通常 24 小时内(工作日优先)完成可行性评估,包括样本量、终点选择、可行的统计路径与潜在审稿风险点。