大型多中心回顾性队列的核心挑战不是建模复杂度,而是选择偏倚与混杂控制的严谨性。一旦 reviewer 发现 immortal time bias 或 collider 调整错误,补救成本极高。
所有图表均为 synthetic illustrative data,由言拓致优内部生成,仅用于方法学路径展示,不指向任何真实患者或客户项目。
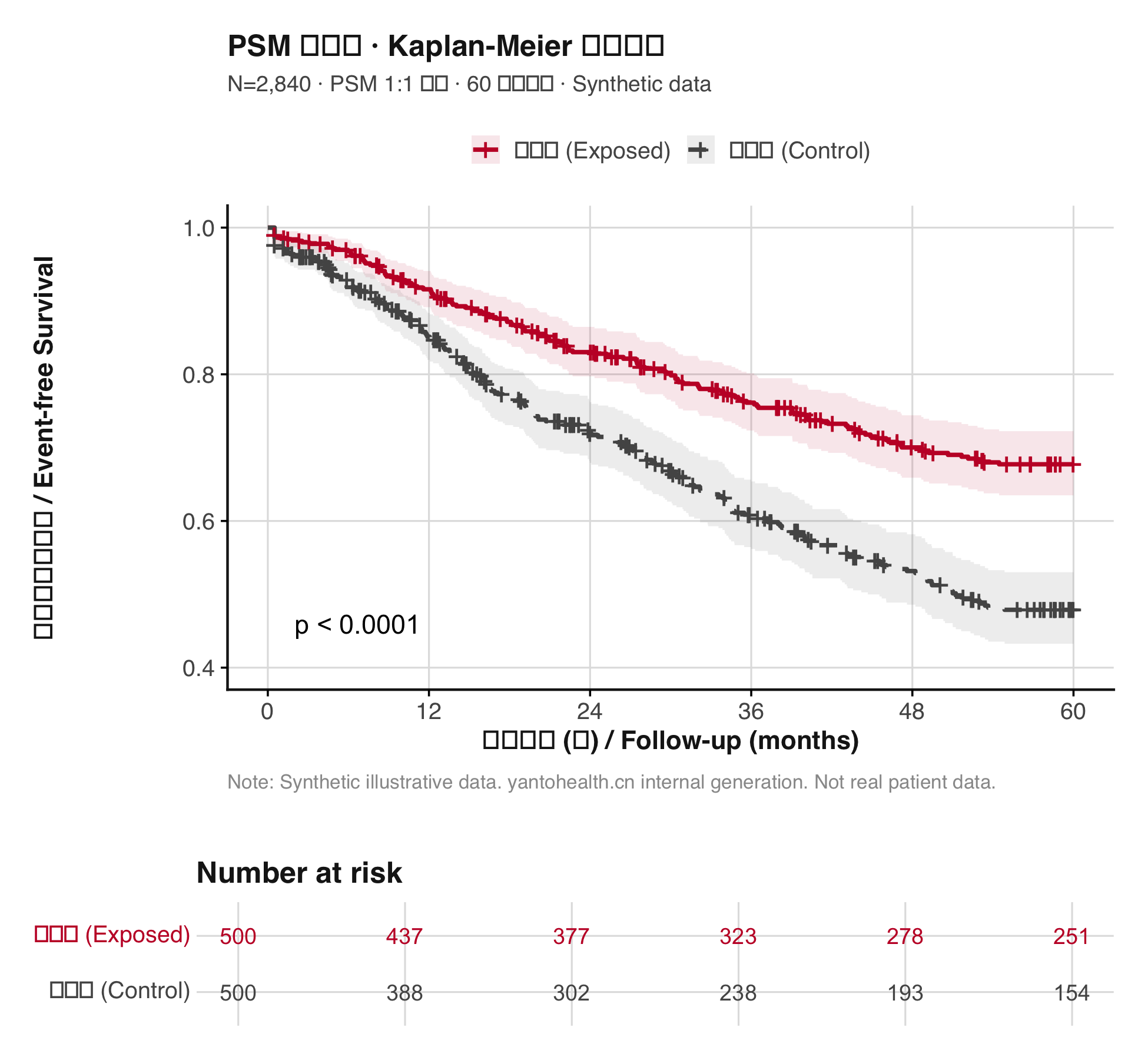
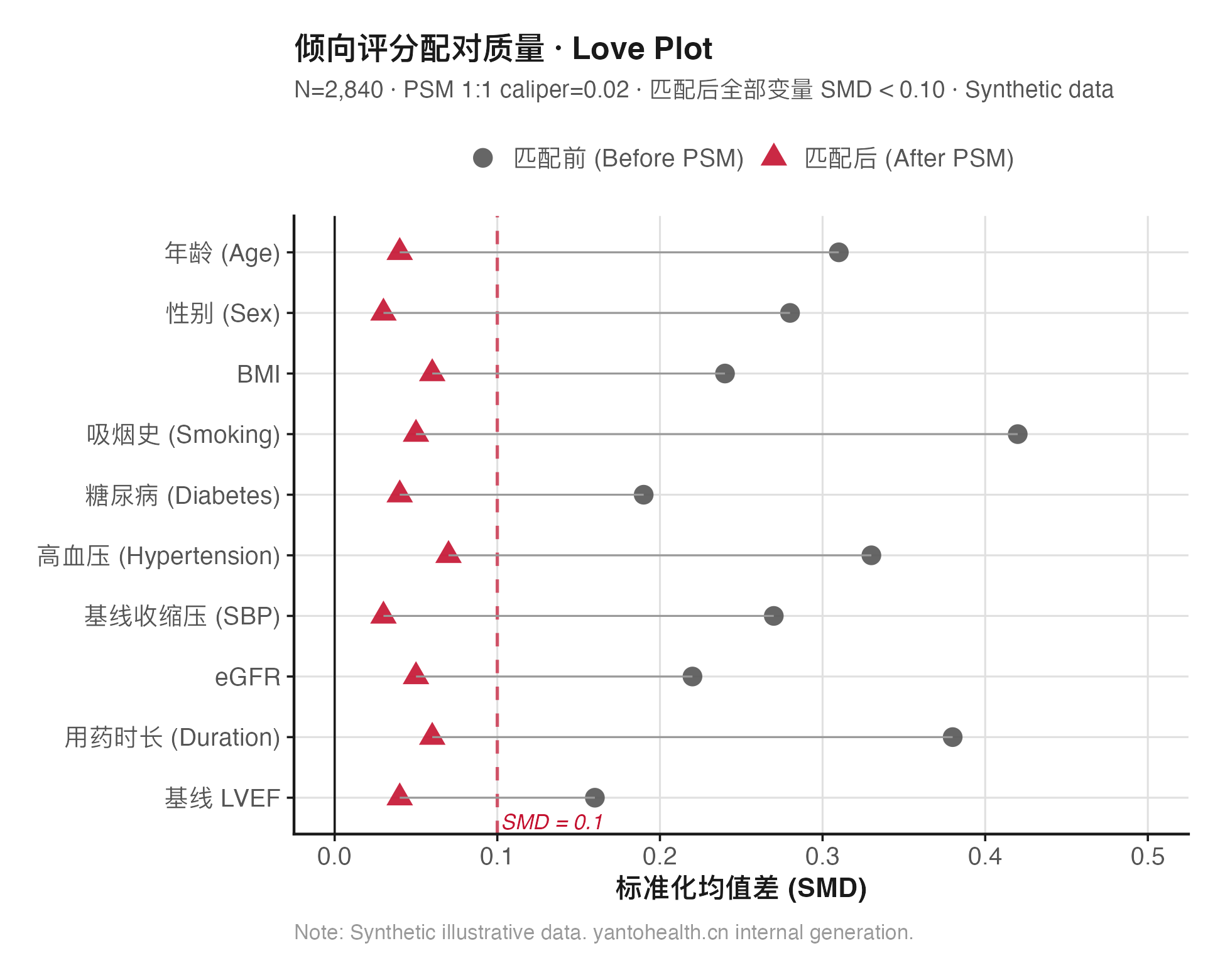
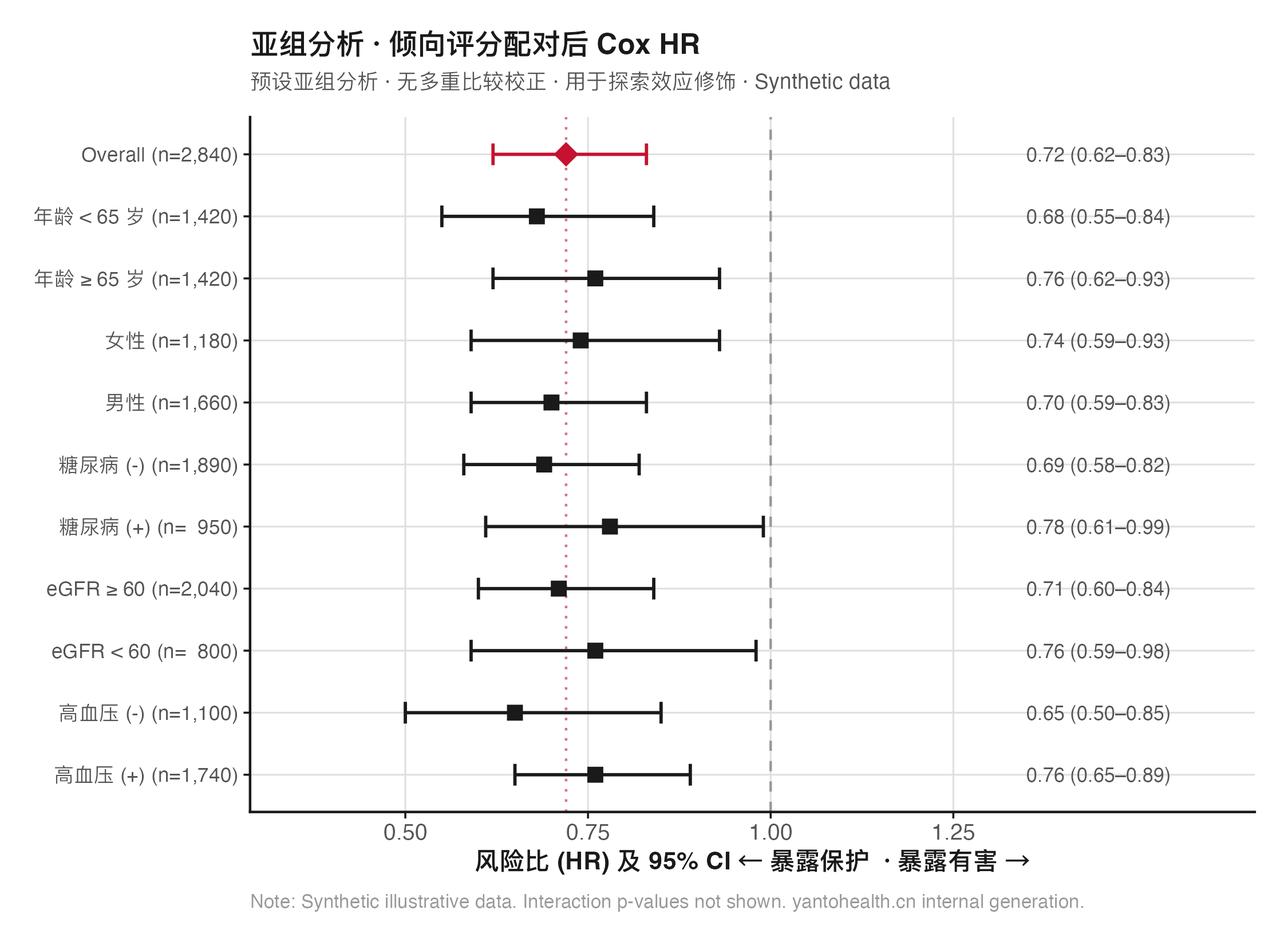
大型多中心回顾性队列研究最常见的发表障碍,不是样本量不够大,而是方法学层面的三类偏倚未被有效控制:选择偏倚(暴露组与对照组基线不可比)、测量偏倚(各中心暴露/结局定义不一致)和混杂偏倚(未区分 confounder、mediator 与 collider 的调整策略)。
reviewer 针对队列研究的质疑高度集中在两个问题:第一,"你用 PSM 配对后,两组基线真的可比了吗?匹配后 SMD 是多少?"。第二,"你调整了这么多变量,有没有考虑 immortal time bias?暴露起点和随访起点是否一致?"。这两类问题如果在建模前没有预设处理策略,投稿后临时补救往往需要重新清洗数据或补充分析,耗时 2–6 周。
本类研究的方法学重点:暴露定义的时间窗精确化 + PSM 配对质量评估 + DAG 驱动的混杂调整 + 至少 2 类敏感性分析(IPTW / 亚组 / E-value)。
多中心数据汇总时,逐中心核查 ICD 编码版本差异、药物暴露定义时间窗、结局终点的判定标准。暴露起点(index date)必须早于随访计时起点,避免 immortal time bias。输出:统一变量字典 + 数据质量核查报告。
在建模前使用 DAGitty 绘制有向无环图,识别混杂因子(调整)、中介变量(不调整或单独分析)、碰撞偏倚(不调整)。基于最小充分调整集(MSAS)选择协变量,而非把所有可测变量都纳入。
采用 caliper=0.02 的最近邻配对,配对后逐变量计算标准化均值差(SMD),目标 SMD<0.1。Love plot 作为图表附件。若 SMD 仍然偏高,切换 caliper 参数或改用 IPTW 替代方案并在方法节说明。
主分析:配对后 Cox 回归(cluster 修正SE),报告 HR + 95% CI + 时间-事件曲线(Kaplan-Meier)。检验比例风险假定(Schoenfeld 残差检验),若违反则引入时依协变量或限制时间窗分层分析。
至少执行 3 类敏感性分析:IPTW 逆概率加权(替代PSM)、主要结局定义宽松/严格版本对比、完整案例分析 vs MICE 多重插补对比。E-value 计算量化残余混杂的最小强度阈值,在讨论节报告。
基于内部 600+ 项目质疑记录整理,不代表特定期刊或审稿人。
通常 24 小时内(工作日优先)完成可行性评估,包括样本量、终点选择、可行的统计路径与潜在审稿风险点。