AUC 0.87 只是起点。Reviewer 的真正问题是:你有没有做外部验证?特征筛选过程有没有数据泄漏?临床决策曲线说明这个模型有实际价值吗?
所有图表均为 synthetic illustrative data,由言拓致优内部生成,仅用于方法学路径展示,不指向任何真实患者或客户项目。
影像组学诊断研究面临三个系统性方法学风险:第一,特征维度远大于样本量("维数灾难")——未经降维直接建模导致严重过拟合,训练集 AUC 漂亮但验证集塌陷;第二,数据泄漏——特征筛选时混入了验证集数据,导致模型表现虚高;第三,临床实用性缺乏证明——只报告 AUC 而不做 DCA 决策曲线分析,reviewer 会质疑"这个模型在临床上有什么实际用处"。
TRIPOD 报告规范是诊断/预测模型研究的投稿必查核单。reviewer 对 TRIPOD 合规性非常敏感:候选预测变量是否预先声明?特征筛选过程是否在训练集内完成?缺失值处理是否在分割前还是分割后进行?这些都是高频质疑点,需要在方法节逐项说明。
本类研究的方法学重点:严格的训练/验证集分割 → 训练集内完成特征筛选 → LASSO / 递归特征消除 → Bootstrap 1000 次内部验证 + 独立外部数据集验证 → DCA 决策曲线分析临床价值 → TRIPOD 报告规范逐条对照。
影像组学特征提取后,先做观测者内(intra-observer)和观测者间(inter-observer)一致性检验(ICC)。ICC<0.75 的特征视为不稳定,在后续建模前剔除。这一步在 TRIPOD 框架中属于"特征工程预筛选",不进入正式特征选择流程。
在任何特征选择之前,先将数据集按 7:3 比例随机分割(或按时间/机构分割用于外部验证)。分割后训练集和验证集完全隔离。缺失值插补、标准化(Z-score 或 Min-Max)均在训练集上拟合,再将参数应用于验证集——验证集的任何信息不可渗透进训练流程。
在训练集内进行两阶段特征筛选:相关性筛选(剔除 Pearson r>0.9 的高度相关特征对)+ 正则化降维(LASSO logistic 回归,通过 10-fold 交叉验证确定最优 λ)。最终选定的特征集不超过样本量/10,防止过拟合。LASSO 路径图作为附件图表提交。
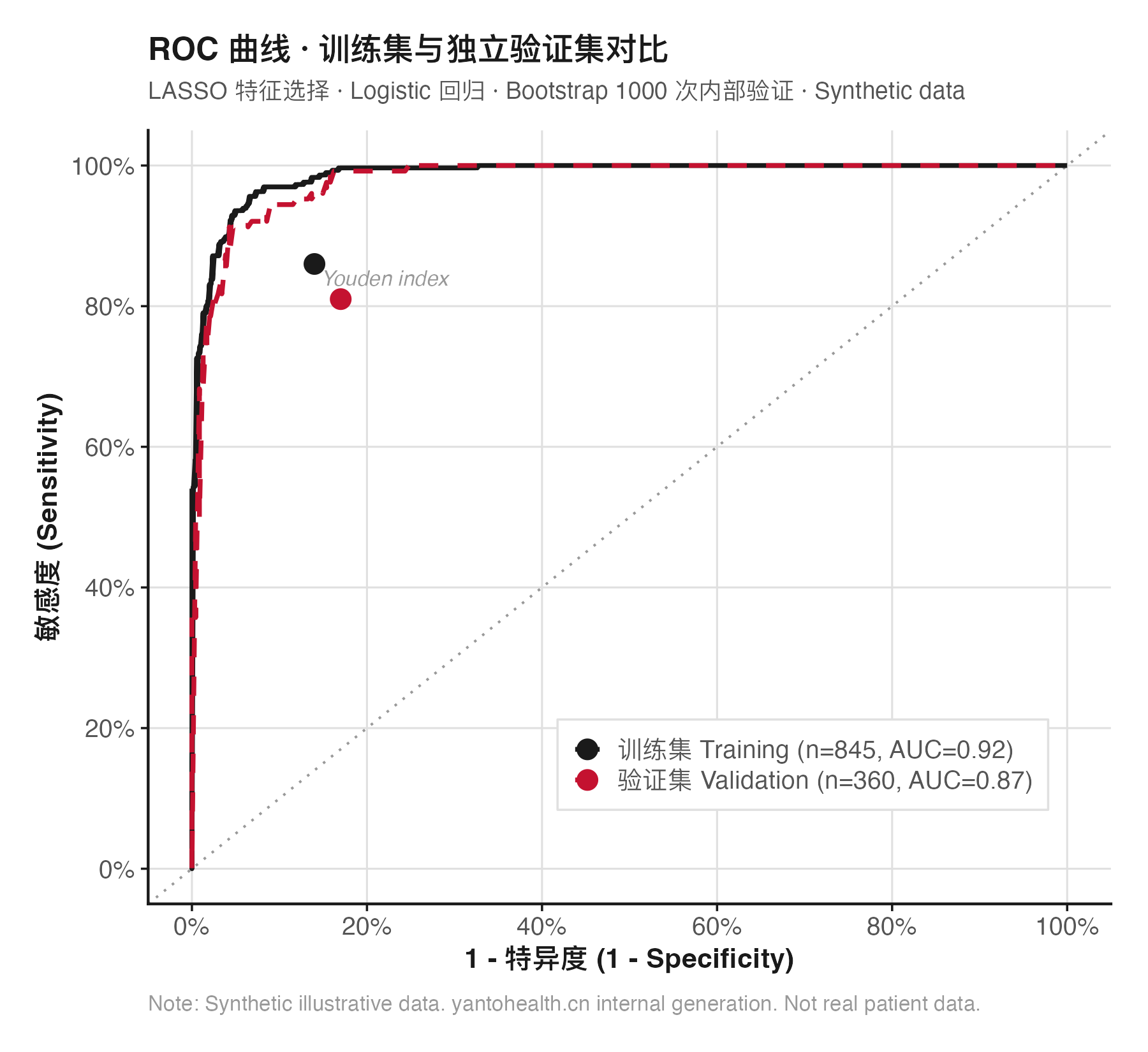
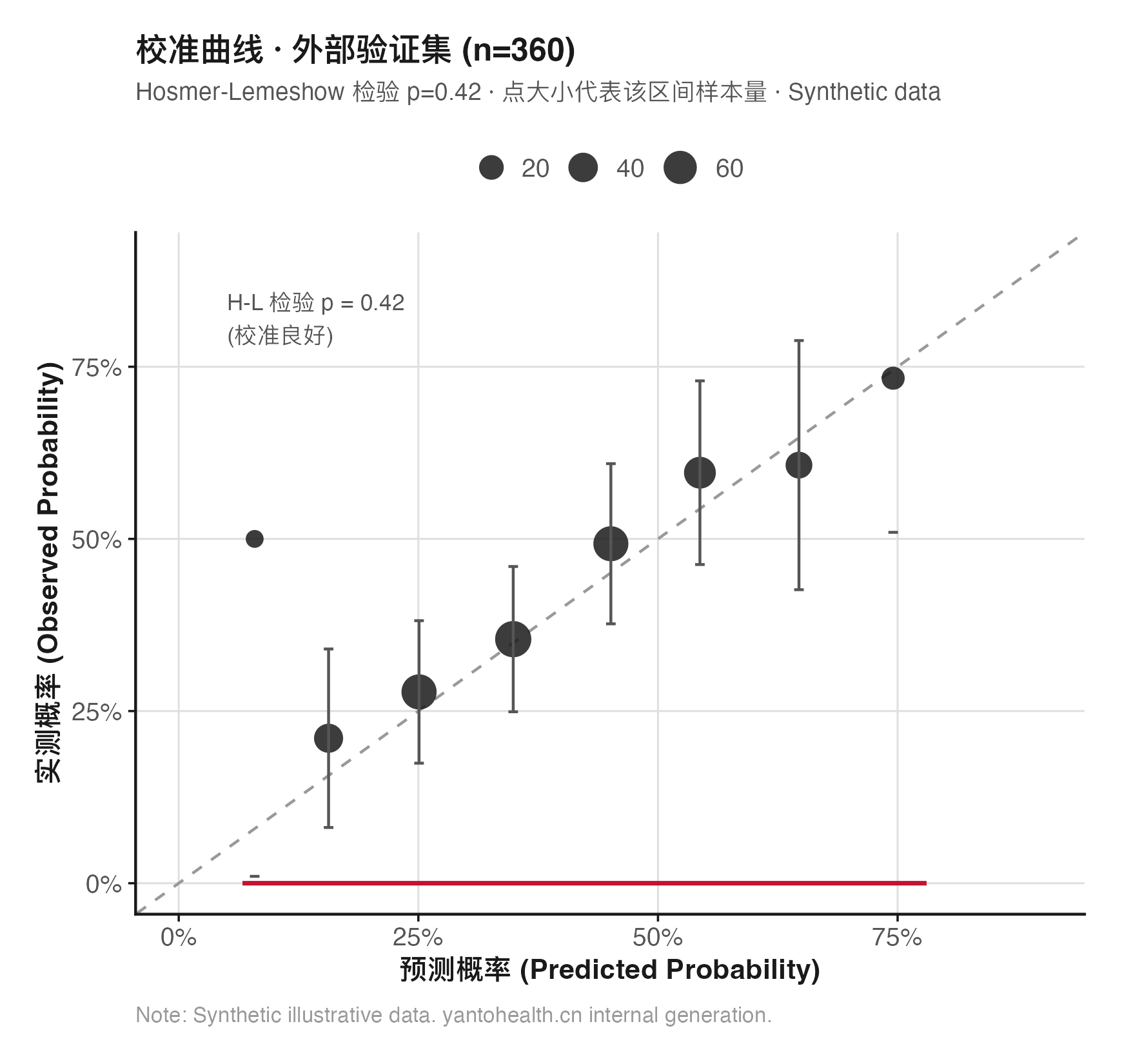
基于 LASSO 筛选特征构建 Logistic 回归模型(或随机森林 / SVM 作为对比)。Bootstrap 1000 次重采样进行乐观性校正,报告原始 AUC 与校正后 AUC 的差值(过拟合程度量化)。校准曲线(Calibration plot) + Hosmer-Lemeshow 检验评估校准度。
在完全独立的外部数据集(不同机构或不同时间段)上评估模型表现:AUC + 95% CI(Delong 法)、敏感性、特异性、阳性/阴性预测值。若 AUC 从训练集到外部验证集下降>0.08,在讨论节说明可能原因(数据来源、扫描设备、人群分布差异)。
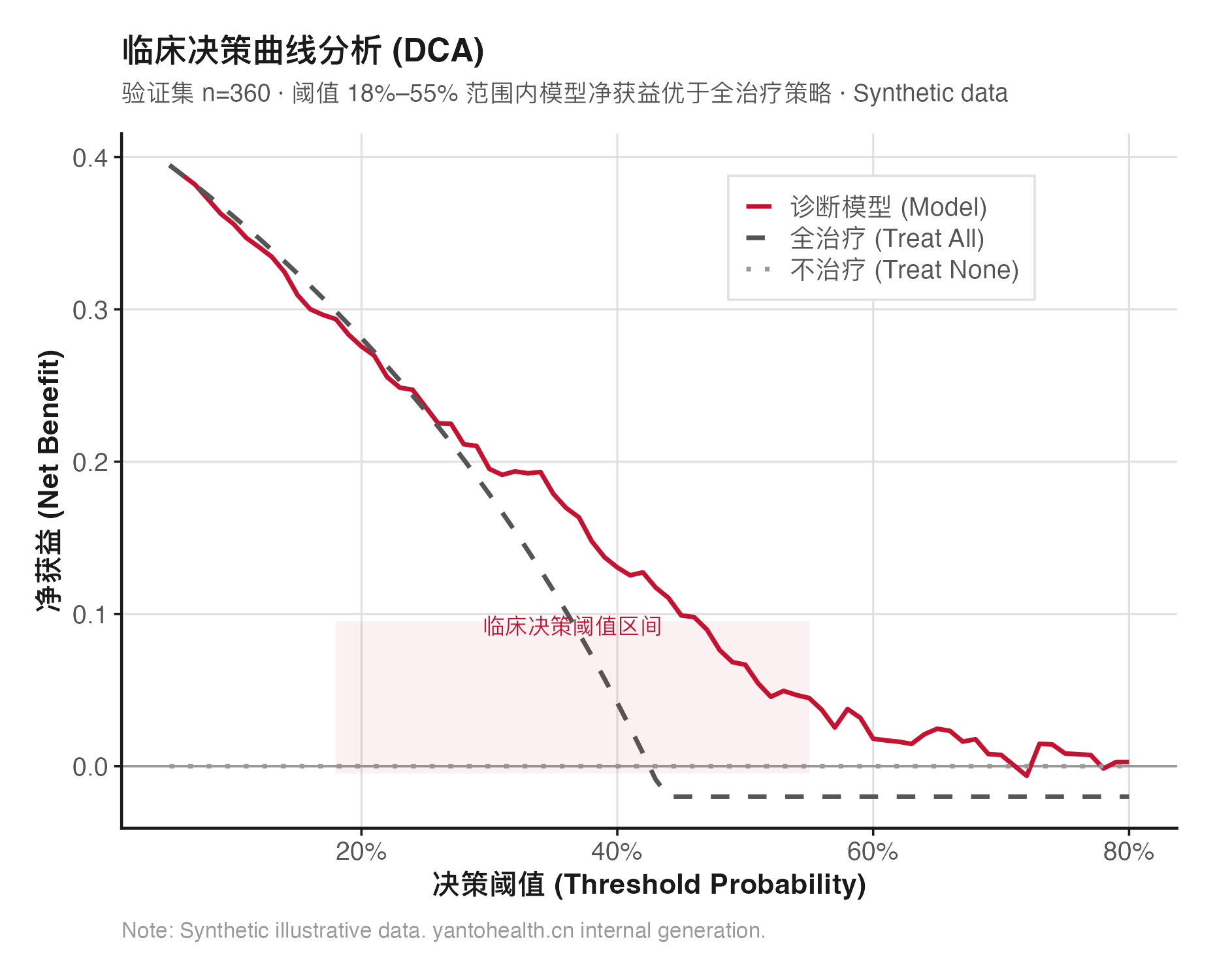
决策曲线分析(DCA)在不同概率阈值下比较模型 vs 全治疗 vs 无治疗的净收益,回答"这个模型在临床上有没有用"。Nomogram 或评分系统可视化模型,提升临床可用性。TRIPOD 逐条核查表随交付打包。
基于内部 600+ 项目质疑记录整理,不代表特定期刊或审稿人。
通常 24 小时内(工作日优先)完成可行性评估,包括样本量、终点选择、可行的统计路径与潜在审稿风险点。